How to Read Sequence File in Pyspark
Imagine you lot are given a job to parse thousands of xml files to extract the information, write the records into table format with proper data types, the job must be done in a timely manner and is repeated every hour. What are you going to practise? With Apache Spark, the embarrassingly parallel processing framework, it can be done with much less effort.
Introduction
In this mail, we are going to utilise PySpark to process xml files to excerpt the required records, transform them into DataFrame, and so write as csv files (or whatever other format) to the destination. The input and the output of this task looks like below. 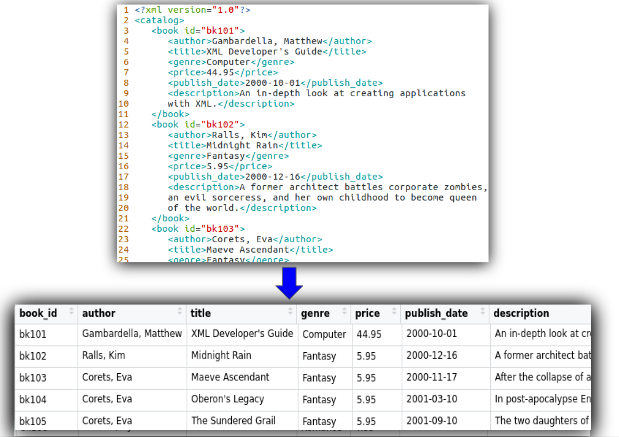
XML files
XML is designed to shop and send data. XML is self-descriptive which makes it flexibile and extensible to store dissimilar kinds of data.
On the other hand, it makes hard to convert into tabular data because of its nature of semi-structured. For example, in the below XML excerption, the description chemical element tin can be expanded to multiple lines. The price element can be omitted considering it is however to exist adamant.
i 2 3 iv 5 vi
<volume id= "bk119" > <author>Feng, Jason</author> <title>Playground</championship> <description>This is the place where Jason puts his fun stuff mainly related with Python, R and GCP.</clarification> </book>
Solution
This is my scribble of the solution. 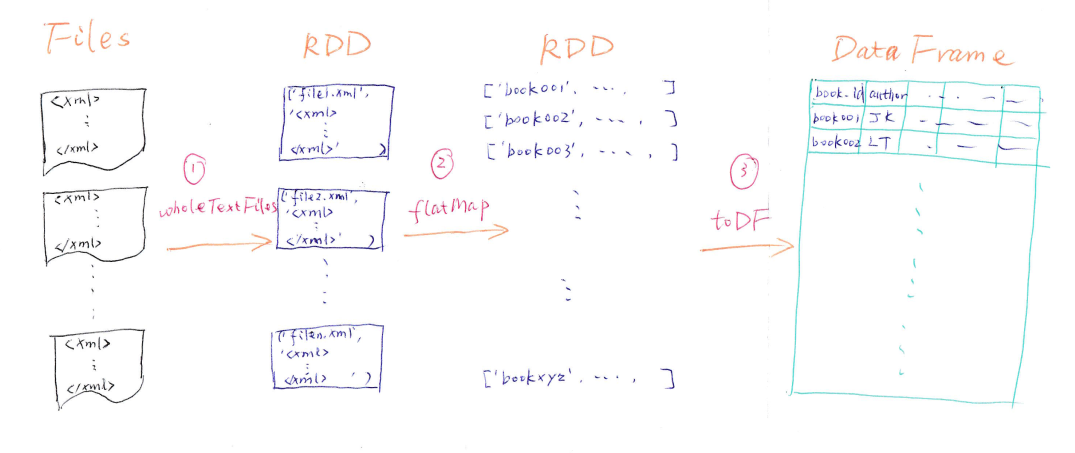
Stride one: Read XML files into RDD
We use spark.read.text to read all the xml files into a DataFrame. The DataFrame is with one column, and the value of each row is the whole content of each xml file. Then we convert information technology to RDD which we can utilize some low level API to perform the transformation.
1 2
# read each xml file every bit one row, then convert to RDD file_rdd = spark . read . text ( "./data/*.xml" , wholetext = True ). rdd
Here is the output of one row in the DataFrame.
1 2
[ Row ( value = '<?xml version="1.0"?> \r\northward <catalog> \r\n <book id="bk119"> \r\north <author>Feng, Jason</author> \r\northward <championship>Playground</title> \r\n <clarification>This is the place where Jason puts his fun stuff \r\n mainly related with Python, R and GCP.</description> \r\northward </book> \r\n </catalog>' )]
Step 2: Parse XML files, extract the records, and expand into multiple RDDs
Now it comes to the cardinal part of the entire process. We demand to parse each xml content into records according the pre-defined schema.
Start, we define a function using Python standard library xml.etree.ElementTree to parse and excerpt the xml elements into a list of records. In this part, we cater for the scenario that some elements are missing which None is returned. It also casts price to float type and publish_date to engagement type.
1 2 3 4 5 six 7 eight 9 ten 11 12 13 14 15 sixteen 17 18 nineteen twenty 21 22 23 24
def parse_xml ( rdd ): """ Read the xml string from rdd, parse and extract the elements, then return a list of list. """ results = [] root = ET . fromstring ( rdd [ 0 ]) for b in root . findall ( 'book' ): rec = [] rec . append ( b . attrib [ 'id' ]) for due east in ELEMENTS_TO_EXTRAT : if b . find ( eastward ) is None : rec . append ( None ) continue value = b . find ( e ). text if e == 'toll' : value = float ( value ) elif e == 'publish_date' : value = datetime . strptime ( value , '%Y-%m-%d' ) rec . append ( value ) results . append ( rec ) render results
Then nosotros utilize flatMap office which each input item as the content of an XML file can be mapped to multiple items through the function parse_xml. flatMap is ane of the functions made me "WoW" when I outset used Spark a few years ago.
1 ii
# parse xml tree, extract the records and transform to new RDD records_rdd = file_rdd . flatMap ( parse_xml )
Step three: Catechumen RDDs into DataFrame
Nosotros so convert the transformed RDDs to DataFrame with the pre-defined schema.
one 2
# convert RDDs to DataFrame with the pre-defined schema book_df = records_rdd . toDF ( my_schema )
The DataFrame looks like below.
1 2 three 4 5 half dozen seven 8 9
+-------+--------------------+--------------------+---------------+-----+------------+--------------------+ |book_id| writer| championship| genre|cost|publish_date| description| +-------+--------------------+--------------------+---------------+-----+------------+--------------------+ | bk101|Gambardella, Matthew|XML Developer's G...| Figurer|44.95| 2000-10-01|An in-depth look ...| | bk102| Ralls, Kim| Midnight Pelting| Fantasy| 5.95| 2000-12-sixteen|A former architec...| | bk103| Corets, Eva| Maeve Ascendant| Fantasy| 5.95| 2000-11-17|Later the collaps...| | bk104| Corets, Eva| Oberon'southward Legacy| Fantasy| 5.95| 2001-03-10|In mail-apocalyps...| | bk105| Corets, Eva| The Sundered Grail| Fantasy| 5.95| 2001-09-10|The 2 daughters...| | bk106| Randall, Cynthia| Lover Birds| Romance| 4.95| 2000-09-02|When Carla meets ...|
Pace 4: Save DataFrame as csv files
Finally we tin can relieve the results as csv files. Spark provides rich set of destination formats, i.e. we can write to JSON, parquet, avro, or even to a table in a database.
1 2 three
# write to csv book_df . write . format ( "csv" ). mode ( "overwrite" )\ . save ( "./output" )
Conclusion
This is merely ane of the showcases of what Spark tin help to simplify the data processing peculiarly when dealing with big amount of data. Spark provides both high-level API (DataFrame / DataSet), and low-level API (RDD) which enables us with the flexibility to handle various types of data format. Spark also abstracts the physical parallel ciphering on the cluster. We just need to focus our codes on the implementation of business logic.
Source codes are here.
Source: https://q15928.github.io/2019/07/14/parse-xml/
0 Response to "How to Read Sequence File in Pyspark"
Post a Comment